今天咱们就来谈谈我学习Linux内核遇到的第一个重要概念,Page Cache
Page Cache是什么
Page cache是操作系统中用来提高磁盘I/O性能的一种内存缓存机制。它将磁盘中的数据(如文件内容)缓存在内存中,当应用程序需要访问这些数据时,系统可以直接从内存读取,而不是每次都去磁盘请求。这样可以大大提高数据读取速度,减少磁盘访问次数。操作系统会在内存中按页面(通常是4KB)存储数据,这些缓存的数据会在系统空闲时自动清理或根据需要被更新到磁盘。下面展示一张图
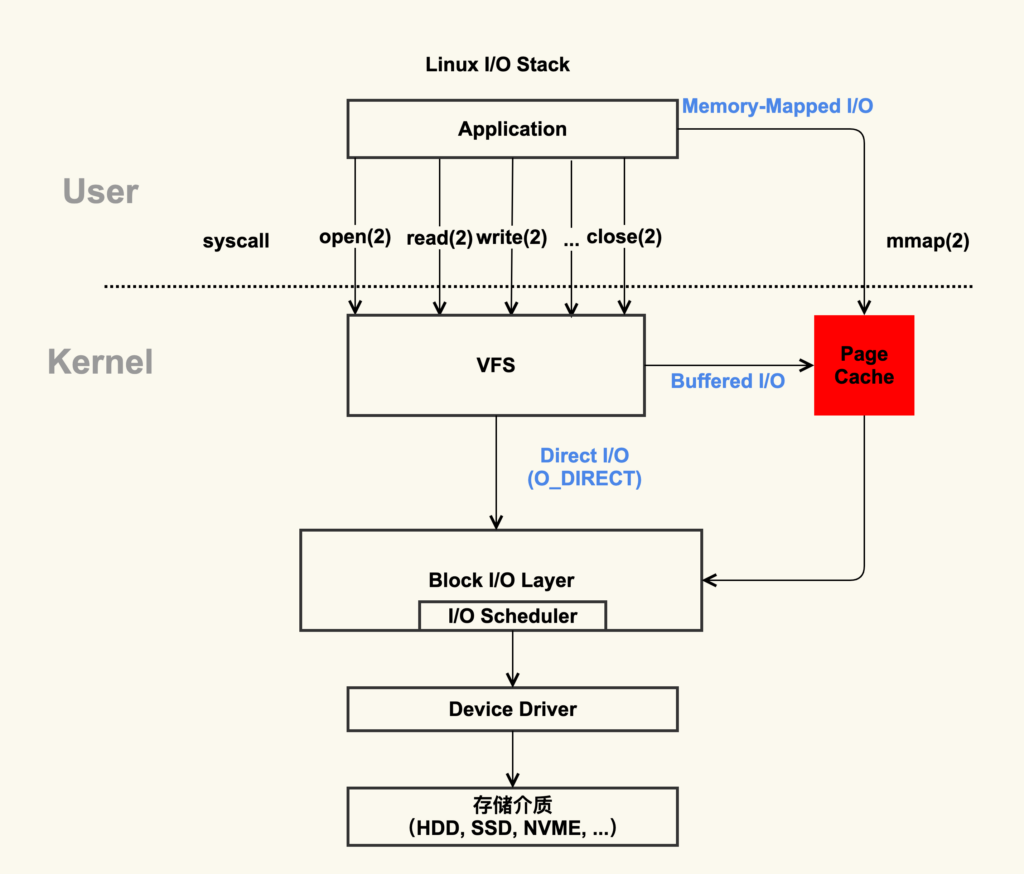
通过这张图片可以清楚地看到,红色的地方就是 Page Cache,很明显,Page Cache 是内核管理的内存,也就是说,它属于内核不属于用户。这张图中的Page Cache还涉及到了一个重要概念,即mmap,我下面会大致描述一下mmap的工作流程
mmap 的映射过程
- 进程调用
mmap- 进程使用
mmap让操作系统建立一个虚拟地址到磁盘文件的映射,但这时并不会立即分配物理内存。 - 操作系统只是记录映射关系,等进程真正访问这个地址时才加载数据。
- 进程使用
- 进程访问映射区域(触发缺页异常)
- 当进程访问
mmap返回的虚拟地址时,CPU 通过 页表(Page Table) 查找对应的物理地址。 - 如果该页尚未被加载到物理内存,会触发 缺页异常(Page Fault)。
- 当进程访问
- 操作系统从磁盘加载数据到物理内存
- OS 发现该页在磁盘上,于是分配一个物理页,并将磁盘中的相应文件内容读取到物理内存。
- 然后更新页表,使得该虚拟地址指向新的物理页。
- 后续访问该地址
- 进程再次访问该地址时,CPU 直接通过页表找到已映射的物理地址,从内存中读取数据,避免磁盘 I/O,提高效率。
观察Page Cache
cat /proc/vmstat
cat /proc/meminfo
这两个文件都可以观察到Page Cache的信息可以得出这样的结论
Buffers + Cached + SwapCached = Active(file) + Inactive(file) + Shmem + SwapCached
这个公式描述了 Linux 内存管理中 Page Cache的组成关系,其中 Buffers、Cached 和 SwapCached 主要代表系统缓存,而 Active(file)、Inactive(file)、Shmem 和 SwapCached 代表这些缓存的分布情况。
Shmem:共享内存(如 tmpfs),属于 Page Cache,但不与具体磁盘文件关联。
Buffers:块设备的 I/O 缓冲区(如磁盘元数据、日志)。
Cached:普通文件的 Page Cache(用于加速文件读取)。
SwapCached:已经交换到 Swap 但仍保留在 Page Cache 中的页(可能被回收)。
Active(file):正在被频繁访问的文件缓存页,优先保留在内存中。
Inactive(file):最近未被访问的文件缓存页,可能被回收。
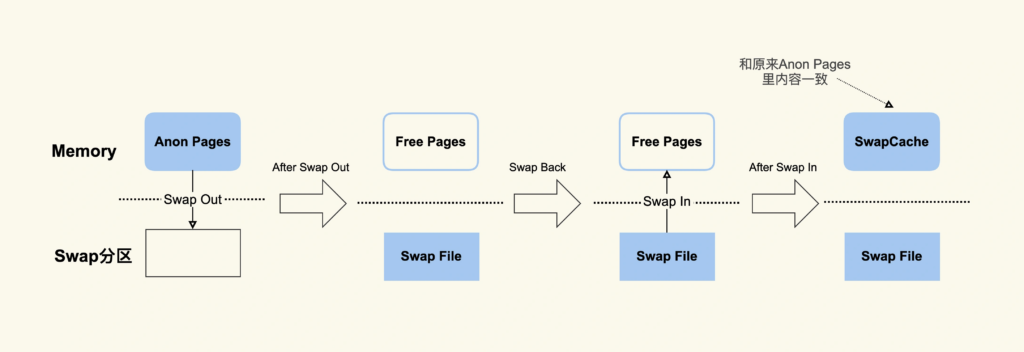
而 SwapCached 是在打开了 Swap 分区后,把 Inactive(anon)+Active(anon) 这两项里的匿名页(没有与任何文件关联的内存页,主要用于进程的堆、栈和共享内存)给交换到磁盘(swap out),

然后再读入到内存(swap in)后分配的内存。由于读入到内存后原来的 Swap File 还在,所以 SwapCached 也可以认为是 File-backed page,即属于 Page Cache,下面用一张图来解释
free命令
ree 命令中的 buff/cache 是由 Buffers、Cached 和 SReclaimable 这三项组成的,它强调的是内存的可回收性,也就是说,可以被回收的内存会统计在这一项。其中 SReclaimable 是指可以被回收的内核内存,包括 dentry 和 inode 等。inode存储文件的元数据,如文件大小、权限、所有者、时间戳等,但不包含文件名;而dentry(目录项)则用于存储文件路径与 inode 之间的映射关系,帮助操作系统快速查找文件的具体位置。当我们访问文件时,dentry 通过缓存路径,减少了访问时对磁盘的查找开销,而 inode 则提供了文件的详细信息和数据存储位置。
Page Cache的产生
Page Cache 的产生有两种不同的方式:Buffered I/O(标准 I/O);Memory-Mapped I/O(存储映射 I/O)
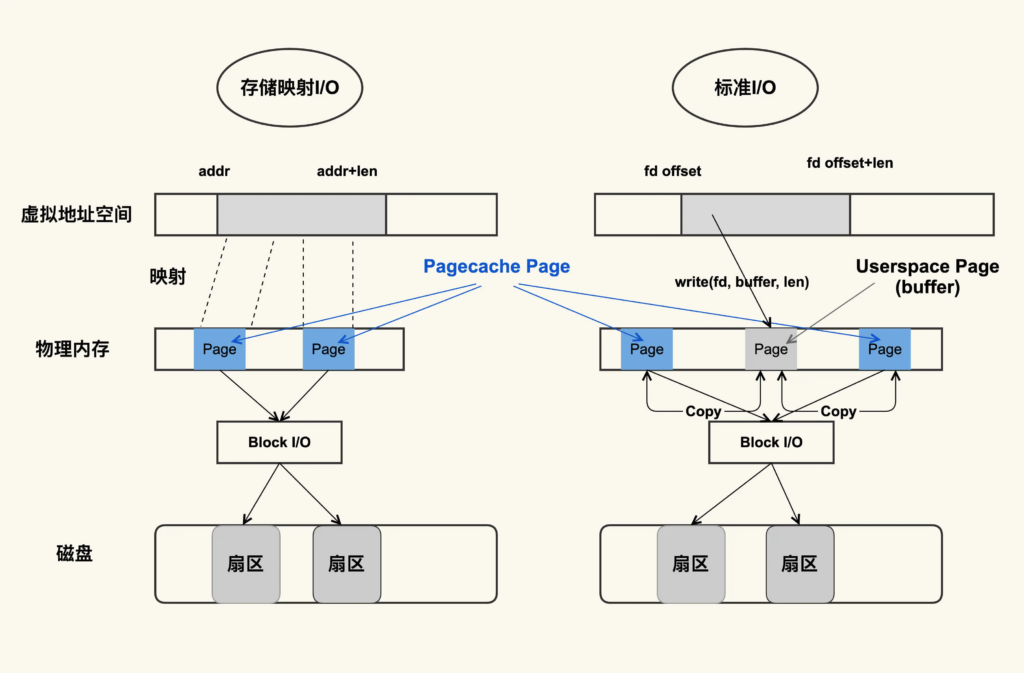
物理内存被划出的page为用户缓冲区(userspace page) 和 内核缓冲区(pagecache page)。标准I/O在虚拟地址空间进行写,会对应到userspace,然后userspace内容拷贝到pagecache;如果是读的话则是先从内核缓冲区拷贝到用户缓冲区,再从用户缓冲区读数据。userspace(buffer)和文件内容不存在任何映射关系。对于存储映射 I/O 而言,则是直接将 Pagecache Page 给映射到用户地址空间,用户直接读写 Pagecache Page 中内容。显然,存储映射 I/O 要比标准 I/O 效率高一些,毕竟少了“用户空间到内核空间互相拷贝”的过程
创建文件的过程
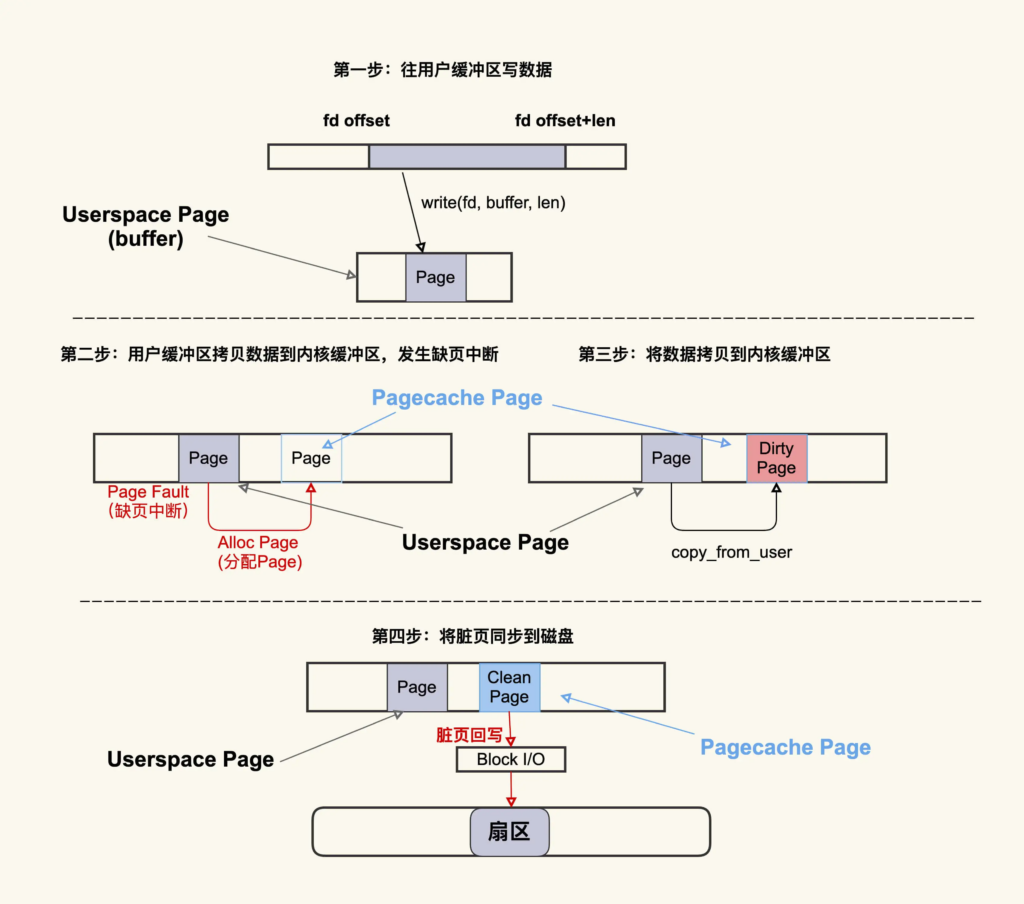
这个过程大致可以描述为:首先往用户缓冲区 buffer(这是 Userspace Page) 写入数据,然后 buffer 中的数据拷贝到内核缓冲区(这是 Pagecache Page),如果内核缓冲区中还没有这个 Page,就会发生 Page Fault 会去分配一个 Page,拷贝结束后该 Pagecache Page 是一个 Dirty Page(脏页),然后该 Dirty Page 中的内容会同步到磁盘,同步到磁盘后,该 Pagecache Page 变为 Clean Page 并且继续存在系统中。
[root@node3 ~]# cat /proc/vmstat | egrep "dirty|writeback"
nr_dirty 1
nr_writeback 0
nr_writeback_temp 0
nr_dirty_threshold 164330
nr_dirty_background_threshold 54776| 参数 | 说明 |
|---|---|
nr_dirty | 当前系统中 脏页(Dirty Pages)的数量(单位:页),即已修改但尚未写入磁盘的数据页。这里值为 1,表示只有 1 页数据尚未写入磁盘。 |
nr_writeback | 当前 正在写入磁盘 的页数,值 0 表示目前没有数据在回写。 |
nr_writeback_temp | 临时写回页,主要用于 NFS 等网络文件系统,通常很少用到,值 0 表示没有临时写回操作。 |
nr_dirty_threshold | 系统触发强制回写的脏页阈值,如果 nr_dirty 超过这个值,写入线程会强制启动数据回写到磁盘。这里值为 164330(单位:页),即约 640MB(假设 4KB 页大小)。 |
nr_dirty_background_threshold | 后台线程启动回写的脏页阈值,当 nr_dirty 超过这个值(54776,约 214MB),pdflush 或 flush 线程会异步启动回写,但不会阻塞应用程序。 |
Page Cache 的“死亡”
你可以把 Page Cache 的回收行为 (Page Reclaim) 理解为 Page Cache 的“自然死亡”。
应用在申请内存的时候,即使没有 free 内存,只要还有足够可回收的 Page Cache,就可以通过回收 Page Cache 的方式来申请到内存,回收的方式主要是两种:直接回收和后台回收。
$ sar -B 1
02:14:01 PM pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
02:14:01 PM 0.14 841.53 106745.40 0.00 41936.13 0.00 0.00 0.00 0.00
02:15:01 PM 5.84 840.97 86713.56 0.00 43612.15 717.81 0.00 717.66 99.98
02:16:01 PM 95.02 816.53 100707.84 0.13 46525.81 3557.90 0.00 3556.14 99.95
02:17:01 PM 10.56 901.38 122726.31 0.27 54936.13 8791.40 0.00 8790.17 99.99
02:18:01 PM 108.14 306.69 96519.75 1.15 67410.50 14315.98 31.48 14319.38 99.80
02:19:01 PM 5.97 489.67 88026.03 0.18 48526.07 1061.53 0.00 1061.42 99.99异步回收是pgscank/s,阻塞回收是pgscand/s 工作主体不同: pgscank/s 来自后台的 kswapd 线程,其目标是预防内存不足,尽可能在应用请求内存前保持充足的可用内存。 pgscand/s 则是由具体应用在分配内存时触发的直接回收行为。 性能影响: 较高的 pgscank/s 数值虽然表示 kswapd 在工作,但一般不会直接影响应用性能,因为它是在后台运行。 较高的 pgscand/s 数值则可能直接影响应用,因为当进程需要等待直接回收完成后才能获得足够内存时,会导致响应延迟。
针对Page Cache进行优化
直接内存回收引起 load 飙高或者业务时延抖动
直接内存回收是在进程申请内存的过程中同步进行的回收,而这个回收过程可能会消耗很多时间,进而导致进程的后续行为都被迫等待,这样就会造成很长时间的延迟,以及系统的 CPU 利用率会升高,最终引起 load 飙高。在开始内存回收后,首先进行后台异步回收(上图中蓝色标记的地方),这不会引起进程的延迟;如果后台异步回收跟不上进程内存申请的速度,就会开始同步阻塞回收,导致延迟
一个解决方案就是及早地触发后台回收来避免应用程序进行直接内存回收
我们先来了解一下后台回收的原理
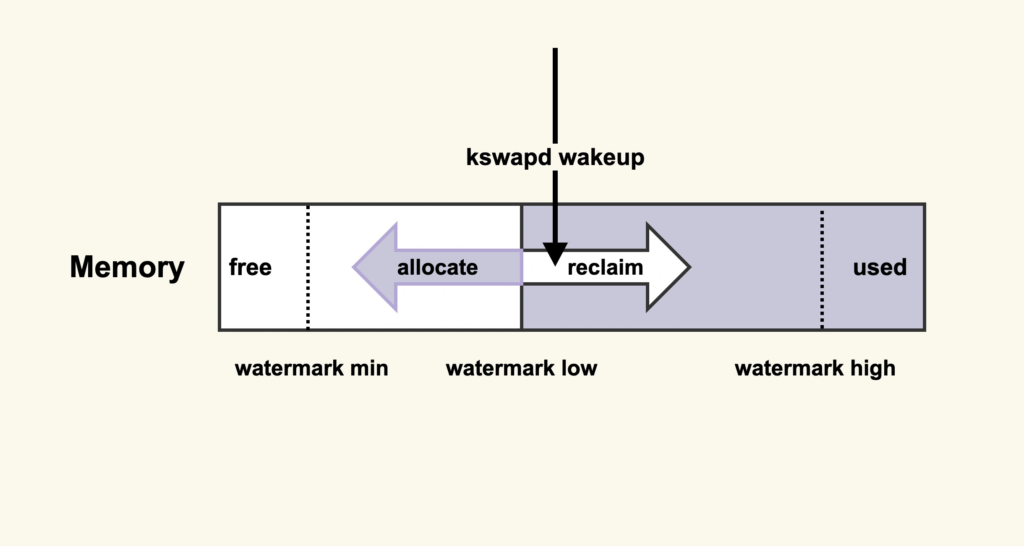
它的意思是:当内存水位低于 watermark low 时,就会唤醒 kswapd 进行后台回收,然后 kswapd 会一直回收到 watermark high。那么,我们可以增大 min_free_kbytes 这个配置选项来及早地触发后台回收,该选项最终控制的是内存回收水位
cat /proc/sys/vm/min_free_kbytes 系统 在这里查看 修改 vi /etc/sysctl.conf vm.min_free_kbytes=524288 sysctl -p 生效这样做也有一些缺陷:提高了内存水位后,应用程序可以直接使用的内存量就会减少,这在一定程度上浪费了内存。所以在调整这一项之前,你需要先思考一下,应用程序更加关注什么,如果关注延迟那就适当地增大该值,如果关注内存的使用量那就适当地调小该值。
调整的效果你可以通过 /proc/zoneinfo 来观察:
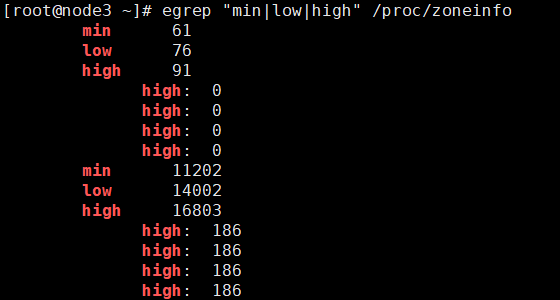
单位为页,这些值是基于 内存区域(zone) 的,不同的内存区域(如 ZONE_DMA、ZONE_NORMAL、ZONE_HIGHMEM)有不同的 min、low 和 high 阈值,反映了系统在不同内存区域的可用内存水平。
系统中脏页过多引起 load 飙高
直接回收过程中,如果存在较多脏页就可能涉及在回收过程中进行回写,这可能会造成非常大的延迟,而且因为这个过程本身是阻塞式的,所以又可能进一步导致系统中处于 D 状态的进程数增多,最终的表现就是系统的 load 值很高。一个比较省事的解决方案是控制好系统中积压的脏页数据
$ sar -r 1
07:30:01 PM kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
09:20:01 PM 5681588 2137312 27.34 0 1807432 193016 2.47 534416 1310876 4
09:30:01 PM 5677564 2141336 27.39 0 1807500 204084 2.61 539192 1310884 20
09:40:01 PM 5679516 2139384 27.36 0 1807508 196696 2.52 536528 1310888 20
09:50:01 PM 5679548 2139352 27.36 0 1807516 196624 2.51 536152 1310892 24
kbdirty 就是系统中的脏页大小
vm.dirty_background_bytes = 0
vm.dirty_background_ratio = 10
vm.dirty_bytes = 0
vm.dirty_expire_centisecs = 3000
vm.dirty_ratio = 20
调整这些配置项有利有弊,调大这些值会导致脏页的积压,但是同时也可能减少了 I/O 的次数,从而提升单次刷盘的效率;调小这些值可以减少脏页的积压,但是同时也增加了 I/O 的次数,降低了 I/O 的效率。系统 NUMA 策略配置不当引起的 load 飙高
推荐将 zone_reclaim_mode 配置为 0。vm.zone_reclaim_mode = 0
配置为 0 之后,就避免了在其他 node 有空闲内存时,不去使用这些空闲内存而是去回收当前 node 的 Page Cache,也就是说,通过减少内存回收发生的可能性从而避免它引发的业务延迟。