作为一个容器集群编排与管理项目,Kubernetes 为用户提供的基础设施能力,不仅包括了应用定义和描述的部分,还包括了对应用的资源管理和调度的处理,我们先从它的资源模型开始说起。
在k8s资源限制中,最重要的莫过于对cpu和memory的限制。在 Kubernetes 中,像 CPU 这样的资源被称作“可压缩资源”。它的典型特点是,当可压缩资源不足时,Pod 只会“饥饿”,但不会退出。而像内存这样的资源,则被称作“不可压缩资源。当不可压缩资源不足时,Pod 就会因为 OOM(Out-Of-Memory)被内核杀掉。常用写法为:
resources:
limits:
cpu: 500m
memory: 128Mi
request:
cpu: 100m
memory: 50Mi其实你也可以把cpu写成cpu: 0.5,但在实际使用时,我还是推荐你使用 500m 的写法,毕竟这才是 Kubernetes 内部通用的 CPU 表示方式。还要注意的是,1Mi=1024*1024;1M=1000*1000。如果你指定了 limits.cpu=500m 之后,则相当于将 Cgroups 的 cpu.cfs_quota_us 的值设置为 (500/1000)*100ms,而 cpu.cfs_period_us 的值始终是 100ms。这样,Kubernetes 就为你设置了这个容器只能用到 CPU 的 50%。而对于内存来说,当你指定了 limits.memory=128Mi 之后,相当于将 Cgroups 的 memory.limit_in_bytes 设置为 128 * 1024 * 1024。
下面再来谈谈QoS模型,当 Pod 里的每一个 Container 都同时设置了 requests 和 limits,并且 requests 和 limits 值相等的时候,这个 Pod 就属于 Guaranteed 类别,而处于Guaranteed 类别的Pod可以通过设置 cpuset 把容器绑定到某个 CPU 的核上,由于操作系统在cpu上进行上下切换的次数建设,容器里应用的性能会得到大幅提。而不是像 cpushare 那样共享 CPU 的计算能力。如下所示:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo
namespace: qos-example
spec:
containers:
- name: qos-demo-ctr
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"而当 Pod 不满足 Guaranteed 的条件,但至少有一个 Container 设置了 requests。那么这个 Pod 就会被划分到 Burstable 类别。比如下面这个例子:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-2
namespace: qos-example
spec:
containers:
- name: qos-demo-2-ctr
image: nginx
resources:
limits
memory: "200Mi"
requests:
memory: "100Mi"而如果一个 Pod 既没有设置 requests,也没有设置 limits,那么它的 QoS 类别就是 BestEffort。比如下面这个例子:
apiVersion: v1
kind: Pod
metadata:
name: qos-demo-3
namespace: qos-example
spec:
containers:
- name: qos-demo-3-ctr
image: nginx实际上,QoS 划分的主要应用场景,是当宿主机资源紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。在我的版本中,Eviction的配置在/var/lib/kubelet/config.yaml。目前,Kubernetes 为你设置的 Eviction 的默认阈值如下所示:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%Eviction 在 Kubernetes 里其实分为 Soft 和 Hard 两种模式。当为hard时,一旦节点到达阈值,则会进入 MemoryPressure 或者 DiskPressure 状态,从而避免新的 Pod 被调度到这台宿主机上(实则是因为给这个宿主机打上了污点)而当 Eviction 发生的时候,kubelet 具体会挑选哪些 Pod 进行删除操作,就需要参考这些 Pod 的 QoS 类别了。首当其冲的,自然是 BestEffort 类别的 Pod。其次,是属于 Burstable 类别、并且发生“饥饿”的资源使用量已经超出了 requests 的 Pod。最后,才是 Guaranteed 类别。并且,Kubernetes 会保证只有当 Guaranteed 类别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态时,Guaranteed 的 Pod 才可能被选中进行 Eviction 操作。所以建议你将 DaemonSet 的 Pod 都设置为 Guaranteed 的 QoS 类型。否则,一旦 DaemonSet 的 Pod 被回收,它又会立即在原宿主机上被重建出来,这就使得前面资源回收的动作,完全没有意义了。
接下来再讲解Kubernetes上的默认调度器,默认调度器的主要职责,就是为一个新创建出来的 Pod,寻找一个最合适的Node,在具体的调度流程中,默认调度器会首先调用一组叫作 Predicate 的调度算法,来检查每个 Node。然后,再调用一组叫作 Priority 的调度算法,来给上一步得到的结果里的每个 Node 打分。最终的调度结果,就是得分最高的那个 Node。
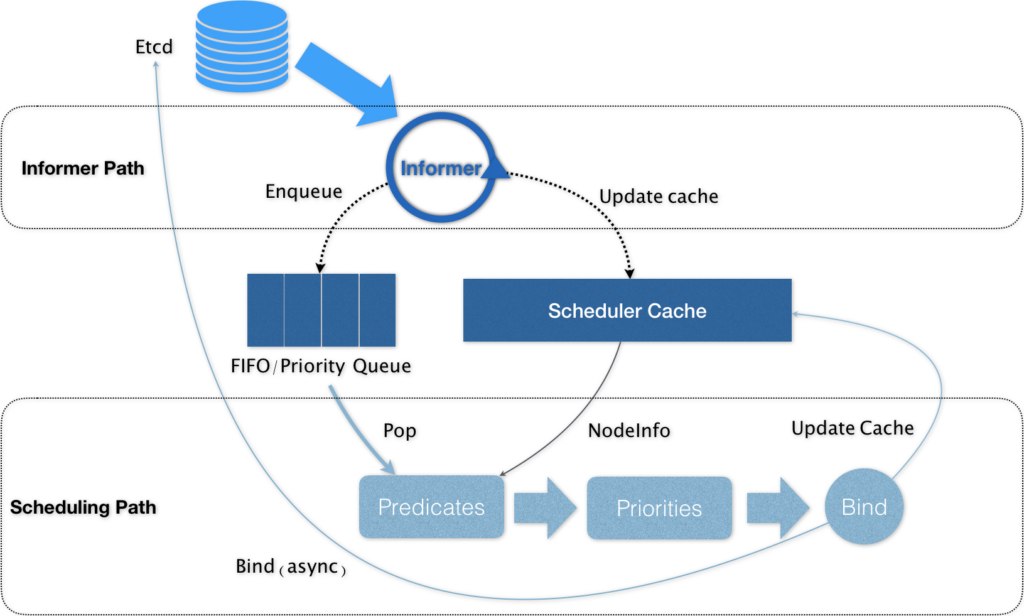
Kubernetes 的调度器的核心,实际上就是两个相互独立的控制循环。
第一个循环:Informer Path。它的主要目的,是启动一系列 Informer,用来监听(Watch)Etcd 中 Pod、Node、Service 等与调度相关的 API 对象的变化。比如,当一个待调度 Pod(即:它的 nodeName 字段是空的)被创建出来之后,调度器就会通过 Pod Informer 的 Handler,将这个待调度 Pod 添加进调度队列。在默认情况下,Kubernetes 的调度队列是一个 PriorityQueue(优先级队列),并且当某些集群信息发生变化的时候,调度器还会对调度队列里的内容进行一些特殊操作。这些特殊操作则是k8s中的优先级与抢占策略。当高优先级的Pod调度失败时,该Pod并不会被搁置,而是会挤走那些低优先级的Pod,而Pod优先级的定义可以参考如下yaml:
apiVersion: scheduling.k8s.io/v1beta1
kind: PriorityClass
metadata:
name: high-priority
value: 1000000
globalDefault: false
description: "This priority class should be used for high priority service pods only."然后在Pod的priorityClassName字段中声明这个PriorityClass的名字就好了。注意,系统 Pod的value默认为10亿(最高),而默认则是0。而 Kubernetes 调度器实现抢占算法的一个最重要的设计,就是在调度队列的实现里,使用了两个不同的队列。第一个队列,叫作 activeQ(即上文的PriorityQueue)。凡是在 activeQ 里的 Pod,都是下一个调度周期需要调度的对象。所以,当你在 Kubernetes 集群里新创建一个 Pod 的时候,调度器会将这个 Pod 入队到 activeQ 里面。调度器会不断从队列里出队(Pop)一个 Pod 进行调度,实际上都是从 activeQ 里出队的。第二个队列,叫作 unschedulableQ,专门用来存放调度失败的 Pod。而这里的一个关键点就在于,当一个 unschedulableQ 里的 Pod 被更新之后,调度器会自动把这个 Pod 移动到 activeQ 里。这次失败事件就会触发调度器为抢占者寻找牺牲者的流程。第一步:调度器会检查此次失败的原因,确定抢占是否可以发生,如果该原因是因为nodeSeletor与node名字都不一样这样之类的原因,那很显然无法进行抢占,无论如何也不会调度成功。第二步:如果确定抢占可以发生,那么调度器就会把自己缓存的所有节点信息复制一份,然后使用这个缓存备份的副本来模拟抢占过程。从最低优先级的Pod开始删除,找出最佳结果。而这一步的判断原则,就是尽量减少抢占对整个系统的影响。比如,需要抢占的 Pod 越少越好,需要抢占的 Pod 的优先级越低越好,等等。在得到了最佳的抢占结果之后,这个结果里的 Node,就是即将被抢占的 Node;被删除的 Pod 列表,就是牺牲者。所以接下来,调度器就可以真正开始抢占的操作了,这个过程,可以分为三步。第一步,调度器会检查牺牲者列表,清理这些 Pod 所携带的 nominatedNodeName 字段。第二步,调度器会把抢占者的 nominatedNodeName,设置为被抢占的 Node 的名字。第三步,调度器会开启一个 Goroutine,同步地删除牺牲者。而第二步对抢占者 Pod 的更新操作后,就会让抢占者在下一个调度周期重新进入调度流程。所以接下来,调度器就会通过正常的调度流程把抢占者调度成功。但对于上述特殊的Pod(即抢占者),在调度时还有特殊的操作,在为某一对 Pod 和 Node 执行 Predicates 算法的时候,如果待检查的 Node 是一个即将被抢占的节点,即:调度队列里有 nominatedNodeName 字段值是该 Node 名字的 Pod 存在。那么,调度器就会对这个 Node ,将同样的 Predicates 算法运行两遍。只有这两遍算法都通过了,才能够认为这个Pod和Node是可以绑定的。
第二个控制循环:Scheduling Path。该循环会不断的从队列中取出一个Pod,接而调用Predicates 算法进行“过滤”。这一步“过滤”得到的一组 Node,就是所有可以运行这个 Pod 的宿主机列表。在这里很重要的一点就是Predicates 算法需要的 Node 信息,都是从 Scheduler Cache 里直接拿到的,这是调度器保证算法执行效率的主要手段之一。接下来,调度器就会再调用 Priorities 算法为上述列表里的 Node 打分,分数从 0 到 10。得分最高的 Node,就会作为这次调度的结果。最后调度器会修改Pod中的nodeName的值,这一步叫做Bind。但是,为了不在关键调度路径里远程访问 APIServer,Kubernetes 的默认调度器在 Bind 阶段,只会更新 Scheduler Cache (这种Cache化是K8s调度器性能提升的关键)里的 Pod 和 Node 的信息。这种 API 对象更新方式,在 Kubernetes 里被称作 Assume。Assume 之后,调度器才会创建一个 Goroutine 来异步地向 APIServer 发起更新 Pod 的请求,来真正完成 Bind 操作。就算这次异步的 Bind 过程失败了,等 Scheduler Cache 同步之后一切就会恢复正常。在Pod完成调度需要运行起来前,该节点上的 kubelet 还会通过一个叫作 Admit 的操作来再次验证该 Pod 是否确实能够运行在该节点上,实则是调用GeneralPredicates最基本的调度算法,比如:“资源是否可用”“端口是否冲突”等再执行一遍,作为 kubelet 端的二次确认。
这就是K8s调度时的基本逻辑,当考虑某一个Pod调度时或在调度时出现了错误,也可以根据这些逻辑来查错。